The task
Following our previous experiments with AI and images we were interested to see whether ChatGPT could be applied to a real world problem. The Langford Brooke Glass Plate Negatives collection consists of around 1000 digitised images which need to be described with metadata. Could ChatGPT assist us with this task, creating tailored descriptions for each photograph as a starting point for the editing process?
Initial experiments
Our digital metadata specialist Ourania Karapasia started sketching out a process for creating this metadata in the ChatGPT web interface. She worked to develop some prompts using the ChatGPT Projects feature, which allows custom instructions to be applied to conversations.
Here are some examples of instructions to guide the metadata creation process for photographs:
- Orientation and Position: Always include the orientation of the people in the shot (e.g., facing front, facing away) along with their position (e.g., sitting, standing). Employ nuanced descriptions of these elements as necessary, but avoid overly detailed or extraneous commentary.
- Restriction on Describing Expressions: Do not describe facial expressions or actions such as smiling or looking directly at the camera.

Description from ChatGPT:
“A child is sitting upright on a saddled donkey on a beach, angled to the left, facing front. The child is wearing a wide-brimmed straw hat, a striped dress with a large collar, and light-coloured stockings. A man is standing beside the donkey, angled to the left, facing front. He is wearing a flat cap, a dark jacket over a buttoned waistcoat and collared shirt, and dark trousers. He is also wearing a neckerchief and heavy lace-up boots. The donkey’s harness and saddle are clearly visible, and the background shows an open, sandy beach under overcast skies.”
Problems with scale
It soon became obvious that there were some problems with this approach:
- Long conversations involving multiple images were difficult to manage. The web interface became very sluggish and the conversation was hard to keep on track.
- It was hoped that through these longer interactions there might be some sort of learning process (ideally, the chatbot would start to recognise people once it had seen enough examples). However, ChatGPT is pre-trained and doesn’t learn from conversations in real time.
Learning and context
A limitation of Large Language Models is that they are expensive to train, requiring large amounts of data and energy. As a result these models are trained and released infrequently. How can these models adapt to different tasks and situations if they don’t change?
Even if the model itself doesn’t change the context it is given can.
One approach is to try to add “memory” to these models. The way this is typically done is by adding extra information into the context (e.g. if you ask ChatGPT to remember to address you in a certain way this hint will be appended to all future conversations).
A similar technique is called Retrieval Augmented Generation (RAG), where parts of documents are injected into the context to help the LLM answer a query, even if the LLM was never trained using those documents.
Managing context
Currently available LLMs appear to achieve better results with short and focussed interactions. ChatGPT is able to use the context that it is given (such as the prompt instructions and any previous text in a conversation) but cannot be relied on to remember facts or to always follow instructions.
Instead of using a workflow involving the ChatGPT website we instead started to investigate automating the process using the ChatGPT API. By creating a new conversation for each photograph we could have much more control over the context that the model was dealing with.
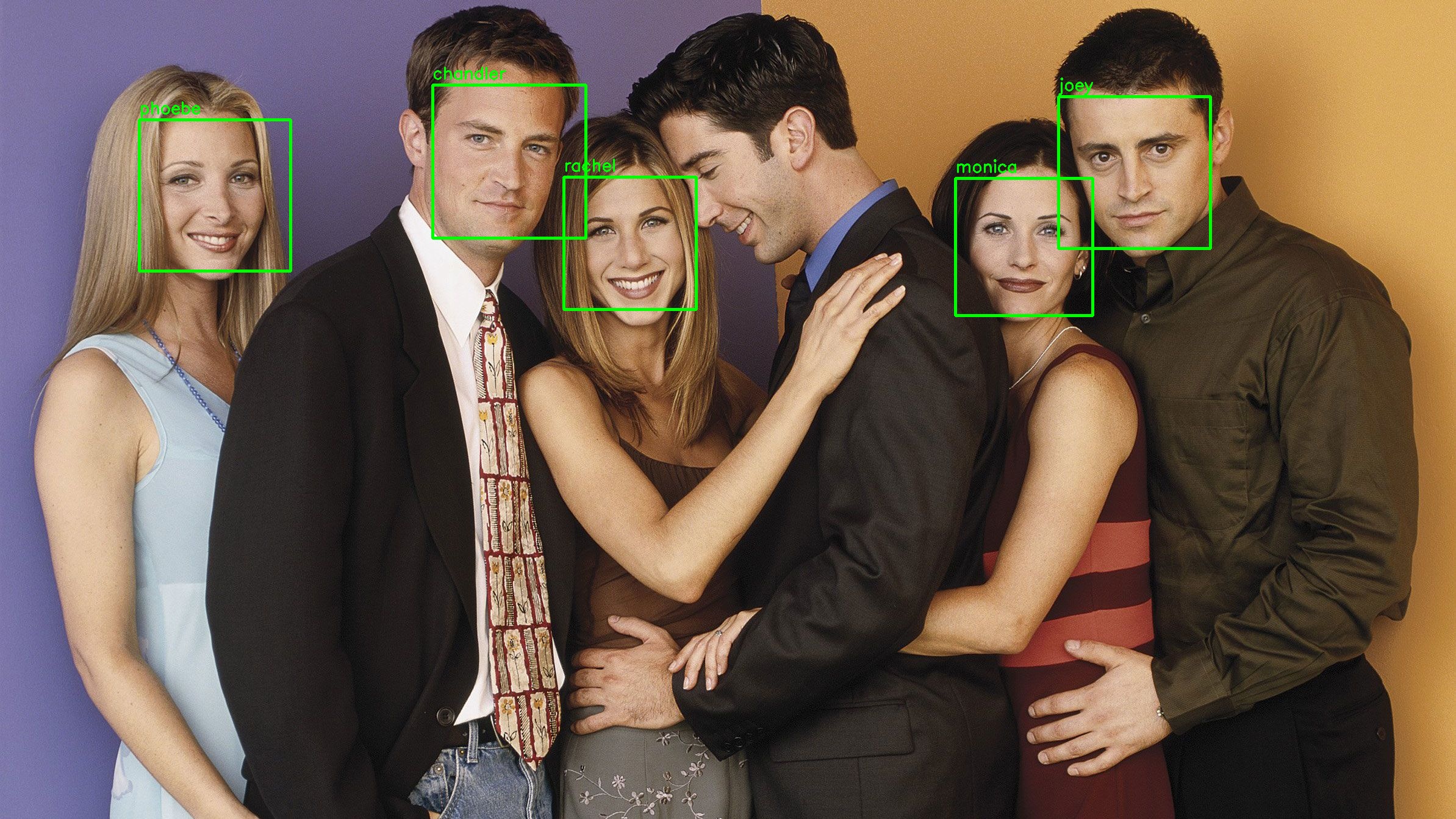
DeepFace
One idea to help with recognising people was to use facial recognition. The open source DeepFace library can both detect and recognise faces in an image, provided that a database of example photos is provided.

If we could identify the faces of people in an image we could feed that into the conversation as context, hopefully leading to more accurate metadata.
For example, a prompt could include the following details when asking for a description of the donkey photograph shown earlier:
“The faces in this image are (from left to right):
Unidentified man
Langford-Brooke, Ronald Prinsep, 1906-1980”
Updated description from ChatGPT:
“An unidentified man is standing angled to the left, facing front. He is wearing a flat cap, dark jacket over a waistcoat, dark shirt with a neckerchief, and loose-fitting trousers with visible turn-ups. Beside him, Ronald Langford-Brooke is sitting on a saddled donkey, angled to the left, facing front. He is wearing a wide-brimmed straw hat and a long-sleeved, striped tunic with buttons down the front, along with white stockings and dark shoes. The donkey is standing on a beach, and the sandy surface is visible underfoot.”
This improved description combines information from the context with details from the image and is more accurate than the previous result (although still far from perfect).
Face detection with early photography
Facial recognition technology has a reputation for being very accurate. However, the nature of early photographic collections poses a challenge. The images are black-and-white, are sometimes quite blurry and tend to have poor contrast.

Our initial results with these images were not good – only about 50% of faces were detected in our sample and of those the majority were not correctly identified. The presence of young children in some examples also added to the challenge, since their faces were quite similar to each other. We plan to revisit this approach with a different set of images and an expanded face database.

Reflections
Although the project is ongoing we have learned a few things about what works and what doesn’t when using ChatGPT with early photographic collections.
By carefully controlling the context given to ChatGPT we saw an improvement in the quality of the descriptions. Keeping interactions short and only including relevant details helped to avoid errors.
Descriptions from ChatGPT are imperfect. They still require checking and editing by a person before being incorporated into metadata.
Automating this process using the API rather than using the web interface is a promising approach and allows us to experiment with more images and variations in prompts.
DeepFace worked well for modern photographs but not so well for early photographs. More (or better) examples of faces in the database could help here, although some of the images in the collection do not have much detail to work with.
Next steps
We plan to continue our attempt to automate this process with four pieces of context per interaction:
- The initial (standard) prompt with guidance on how to describe photographs.
- Some common information about the family and the collection.
- An individual photo.
- A short human-written description of the photo (essentially a title) which identifies the people in it and the general location/topic.
Tom Higgins (Senior Software Developer)